데이터엔지니어링_Dataframe in Spark_Select,Where 함수, spark로 sql 사용하기
2025.09.06

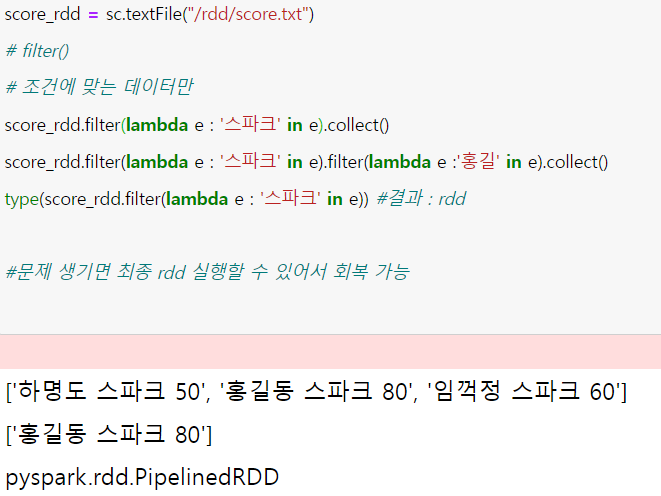
1.select() : 추출할 컬럼 명 선택-> 리스트로도 추출할 수 있음 2.col() colRegex(열) : 정규식에 부...
출처
https://blog.naver.com/sju02083/222878139220
이슈모어 핫이슈








관련 포스팅








Copyright blog.dowoo.me All right reserved.