[데이터시각화_우수상]전기차 충전소 현황 및 교통량에 따른 제언
2025.09.06

멀티캠퍼스 데이터 사이언스 & 엔지니어링반의 데이터 시각화 1차 프로젝트에서 제가 우수상 받았던 프...
출처
https://blog.naver.com/sju02083/222896664290
이슈모어 핫이슈








관련 포스팅
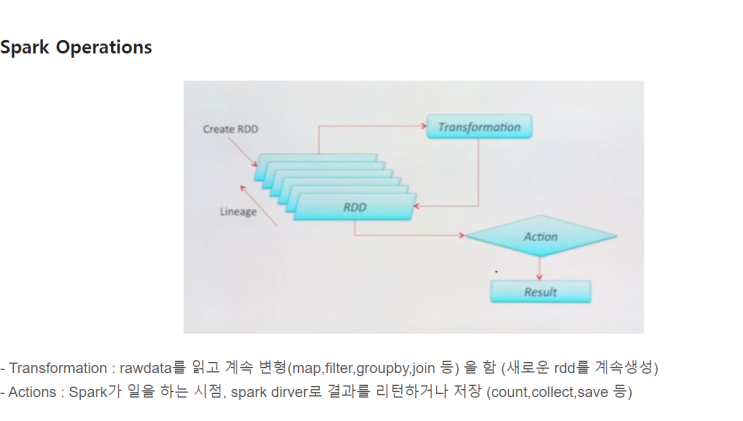

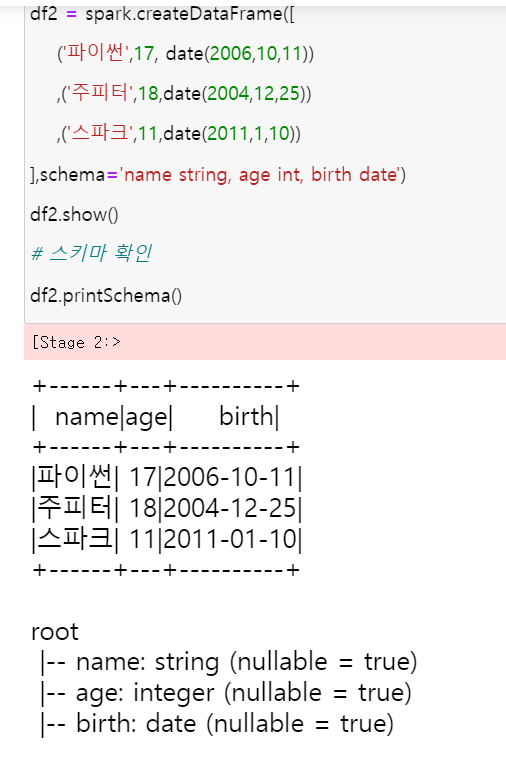




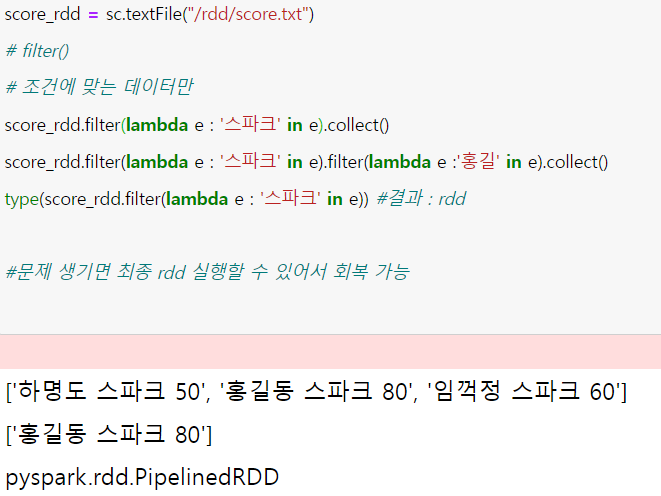


Copyright blog.dowoo.me All right reserved.